









Hallo, MyHeritage-Team,
Vielen Dank für die Info’s.
Bisher habe ich zwar meine DNA-Matches angesehen, doch mit der Auswertung in Bezug auf die Suche nach Verwandten nicht so gute Ergebnisse erzielt.
Jetzt klappt das schon besser.
Ich freue mich auf die Zukunft.
Mit freundlichen Grüßen
Barbara Nitschke
Bedeutende Updates und Verbesserungen des MyHeritage DNA Matching
Wir freuen uns, wichtige Aktualisierungen und Verbesserungen für das DNA-Matching bekannt geben zu dürfen, die ab sofort für alle unsere Nutzer verfügbar sind. Jeder, der einen MyHeritage DNA-Test durchgeführt hat, und jeder, der DNA-Daten aus einem anderen Dienst hochgeladen hat, erhält nun genauere DNA-Übereinstimmungen, mehr Matches (ca. 10x mehr); weniger falsche Positive; spezifischere und genauere Beziehungsschätzungen; und Hinweise auf DNA-Übereinstimmungen mit geringerem Vertrauen, um sich auf die Forschung zu fokussieren. Die seit längerem gewünschte Chromosomenbrowser-Funktion haben wir nun auch hinzugefügt, siehe weiter unten.
An diesen Verbesserungen hat unser Wissenschaftsteam viele Monate gearbeitet. Sie haben viel Zeit und Mühe investiert, weil wir die Wissenschaft perfektionieren und unseren Nutzern optimale Ergebnisse liefern möchten.
Was ist das DNA Matching?
MyHeritage DNA hat derzeit mehr als eine Million Menschen in der DNA-Datenbank. 1,075 Millionen um genau zu sein. DNA-Matching vergleicht DNA-Kits in der MyHeritage-Datenbank miteinander, um Verwandte zu finden, d.h. Personen, die DNA-Segmente miteinander teilen, und um zu erklären, wie diese Personen miteinander verwandt sind. Das Vorhandensein gemeinsamer DNA-Segmente zwischen zwei Personen kann auf eine Blutsverwandtschaft hinweisen, was bedeutet, dass die gemeinsamen Segmente von einem gemeinsamen Vorfahren geerbt wurden. Wenn die geteilten Segmente zahlreich und groß sind, ist eine Blutsverwandtschaft sicherer. Auf der anderen Seite, sollten die geteilten Segmente in der Anzahl und Größe klein sein, kann es auch eine Frage des Zufalls sein, dass überhaupt keine Blutsverwandtschaft anzeigt wird. Wenn eine Übereinstimmung gemeldet wird, obwohl es sich überhaupt nicht um einen Verwandten handelt, ist sie falsch positiv.
Wenn ihr einen MyHeritage DNA-Test durchgeführt und die Ergebnisse erhalten habt oder eure DNA-Daten bei MyHeritage hochgeladen habt, erhaltet ihr eine Liste eurer DNA-Übereinstimmungen. Die Matches werden täglich aktualisiert und die Nutzer werden wöchentlich per E-Mail über die besten neuen Matches informiert. Mit „am besten“ meinen wir die Übereinstimmungen mit der größten Menge an gemeinsamer DNA, was auf eine engere Beziehung hinweist. Die Liste der DNA-Übereinstimmungen zeigt Personen, die DNA-Segmente mit euch teilen, die Menge und den Prozentsatz der DNA, die ihr teilt, die Anzahl der DNA-Segmente, die ihr teilt, und die Größe des größten gemeinsamen Segments. MyHeritage schätzt auch die Beziehung durch die Analyse der Anzahl und Größe der gemeinsamen DNA-Segmente in jeder Übereinstimmung und vergleicht sie mit einem Referenzpool von Hunderttausenden anderer Übereinstimmungen anhand bekannter Beziehungen gemäß Stammbäumen, die durch DNA bestätigt wurden. Die Seite „DNA Match überprüfen“ bietet Hinweise, die ihr verfolgen könnt, um eure Abstammung zurück zu eurem gemeinsamen Vorfahren zu verfolgen.
Ab sofort sehen Nutzer, die zuvor DNA-Matches erhalten haben, nach diesen Verbesserungen, modifizierte und verbesserte Matches. Dies bedeutet, dass viele neue Übereinstimmungen angezeigt werden. Einige zuvor gefundene Übereinstimmungen, die falsch-positiv waren, werden verschwinden. Bei vielen Übereinstimmungen wurden ihre Parameter (z. B. die Menge der gemeinsamen DNA) zu genaueren Werten geändert. Nutzer, die noch keine Matches erhalten haben, erhalten vom ersten Tag an die Matches in höherer Qualität.
Wie funktioniert das DNA Matching?

Schematische Darstellung der Pipeline, die DNA-Übereinstimmungen erzeugt.
Beginnen wir mit einem kurzen Überblick darüber, wie das DNA-Matching funktioniert. Dann werden wir uns mit den Verbesserungen befassen, die wir in den verschiedenen Phasen des Prozesses gemacht haben.
Der Prozess beginnt, sobald ihr einen DNA-Test macht und eure Probe an unser Labor schickt. Im Labor lesen wir eure DNA und erstellen eine Datei mit den Informationen. Wir lesen nicht jeden Teil eurer DNA, die etwa 3 Milliarden Punkte beträgt. Dies ist eine teure Methode, die als Sequenzierung des gesamten Genoms bezeichnet wird und derzeit spezifischen klinischen und Forschungsanwendungen vorbehalten ist. Stattdessen konzentrieren wir uns auf das Lesen von ungefähr 700.000 Stellen in eurer DNA, von denen bekannt ist, dass sie zwischen Individuen variieren, so genannte Einzelnukleotid-Polymorphismen (SNPs, ausgesprochen „Snips“). Diese Methode wird als Genotypisierung bezeichnet und erzeugt eine Datendatei, in der jede SNP, die wir lesen, ihre Position in eurer DNA und die zwei Genotypen, die wir dort gefunden haben (z.B. A, T, G oder C, die ihr von jedem Elternteil geerbt habt) aufgeführt sind. Wenn ihr DNA-Daten von einem anderen Dienst hochgeladen habt, erhalten wir die Datendatei mit denselben Informationen.
Als nächstes verwenden wir Imputation, um die SNPs, die wir nicht gelesen haben, abzuleiten. Vergleicht die Imputation der DNA mit dem Lesen eines Satzes, wo einige der Buchstaben fehlen – es besteht eine gute Chance, dass ihr die fehlenden Buchstaben aus dem Zusammenhang ableiten könnt. Nicht alle DNA-Dienstanbieter lesen die gleichen SNPs. Um DNA-Übereinstimmungen für Personen zu finden, die verschiedene DNA-Dienstanbieter verwendet haben, ist es wichtig, die SNPs, die nicht gelesen wurden, abzuleiten, bevor die Ergebnisse verglichen werden. Einige Leute stellen die Genauigkeit der Imputation in Frage. Wir haben jedoch festgestellt, dass diese Methode bei richtiger Anwendung sehr genau ist und in einigen Situationen unvermeidlich ist.
Nach der Imputation kommt das Phasing. In jedem Chromosomenpaar erhält jede Person einen Chromosomen von der Mutter und einen vom Vater. Die Genotypisierungstechnologie, die eure DNA-Probe liest, bestimmt, welche Genotypen ihr von euren Eltern für jedes SNP geerbt habt, aber sie sagt uns nicht, welche Gruppen von Varianten von demselben Elternteil mitvererbt wurden. Das Phasing hilft uns, das zu klären. Sie gruppiert alle Varianten, die von einem eurer Elterneile in einem Bucket übernommen wurden, und die Varianten, die vom anderen Elternteil in einem anderen Bucket geerbt wurden.
Der nächste Schritt besteht darin, den tatsächlichen Abgleich durchzuführen und alle DNA-Kits in der Datenbank zu vergleichen. Wir tun dies auf einem sehr skalierbaren System namens Hadoop, das uns eine sehr effiziente verteilte Verarbeitung ermöglicht. Matching identifiziert die geteilten Segmente zwischen jedem Paar von Kits, aus denen die Beziehung der zwei Individuen (falls vorhanden) abgeleitet werden kann. Benachbarte gemeinsame Segmente werden dann „zusammengefügt“, wenn sie als zusammenhängend betrachtet werden.
Schließlich verwenden wir fortschrittliche statistische Algorithmen, die Klassifikatoren genannt werden, um die DNA-Übereinstimmungen zu überprüfen und falsche Positive abzulehnen, das Vertrauensniveau der nicht zurückgewiesenen Übereinstimmungen zu bestimmen und die Art der Beziehung für jede Übereinstimmung vorzuschlagen. So erstellen wir eure Liste der DNA-Übereinstimmungen.
Wie haben wir das DNA-Matching verbessert?
Wir haben die Genauigkeit unserer Imputation signifikant verbessert, indem wir die Anzahl der Referenzgenome mehr als verzehnfacht haben. Genauso wie das Lesen von 10-mal so vielen Büchern es einer Person ermöglichen würde, fehlende Buchstaben aus mehreren Sätzen genauer abzuleiten, hat die Erhöhung unseres Referenz-Genompanels unsere Fähigkeit, SNPs, die wir nicht gelesen hatten, genauer zu imputieren, stark erhöht.
Wir haben das Phasing korrigiert. Die vorherige Verarbeitung von DNA-Übereinstimmungen hatte gelegentlich Fehler in der Phase des Phasing. Diese Fehler führten zu einigen falsch positiven Ergebnissen, bei denen wir zuvor gemeinsame Segmente sehr entfernter Verwandter überschätzten. Es führte auch zu Problemen, bei denen wir früher gemeinsame Segmente von nahen Verwandten unterschätzten. Wir verwenden jetzt einen besseren Algorithmus, der diese Fehler beim Phasing korrigiert.
In der Übereinstimmungsphase haben wir den Schwellenwert für Genotypisierungsfehler neu kalibriert. Die Technologie, die eure DNA-Probe liest, macht gelegentlich Fehler. Dies nennt man Genotypisierungsfehler. Wenn ein Genotypisierungsfehler in der Mitte eines gemeinsamen Segments zwischen den DNA-Übereinstimmungen auftritt, scheint dieses Segment nicht identisch zu sein und es kann in zwei übereinstimmende, kleinere Segmente, aufgeteilt werden. Wir haben den Schwellenwert neu kalibriert, sobald kleine Unstimmigkeiten zwischen ansonsten übereinstimmenden Segmenten ignoriert werden, und stattdessen die freigegebenen Segmente trotz kleiner Teile, die nicht übereinstimmen, als identisch behandelt. Diese Methode kompensiert unvermeidbare Genotypisierungsfehler. Wenn wir nicht übereinstimmende Abschnitte, die zu groß sind, ignorieren, gehen wir zufällig davon aus, dass ein Segment geteilt wird, obwohl dies nicht der Fall ist. Wenn wir nicht übereinstimmende Abschnitte ignorieren, die das Ergebnis von Genotypisierungsfehlern sind, werden wir wahrscheinlich echte DNA-Übereinstimmungen verpassen. Die neue Kalibrierung ist strenger als die vorherige, was bedeutet, dass weniger Fehlalarme passieren.
Entferntere Matches sind jetzt erlaubt. Nachdem wir die Genauigkeit der Matches erhöht und die oben genannten Parameter kalibriert hatten, fühlten wir uns wohl dabei, euch weiter entfernte Matches zu präsentieren. Zuvor war das Minimum an gemeinsamer DNA für eine Übereinstimmung 12 cM und jetzt ist das Minimum 8 cM. Dies zusammen mit den anderen Verbesserungen führte zu einer Verzehnfachung der Anzahl der DNA-Übereinstimmungen, die unsere Nutzer jetzt erhalten.
Diese Übereinstimmungen werden automatisch für jeden angezeigt, der bereits einen MyHeritage DNA-Test durchgeführt hat, oder für jeden, der seine DNA bereits in der Vergangenheit bei MyHeritage hochgeladen hat und auch für alle, die dies in Zukunft tun werden.
Bessere Naht von benachbarten Segmenten. Zusätzlich zum Kompensieren von Genotypisierungsfehlern innerhalb von Segmenten ist es notwendig, die verbleibenden Phasenfehler zwischen Segmenten zu kompensieren. Zum Beispiel wird erwartet, dass eine Mutter und eine Tochter in einem autosomalen DNA-Test 22 übereinstimmende Segmente haben, ohne das Geschlechtschromosom zu berücksichtigen: Ein ganzes Chromosom von jedem der Chromosomenpaare der Tochter wurde von ihrer Mutter geerbt, und so sollte jedes der 22 autosomalen Chromosomen ein einzelnes, langes, passendes Segment sein. Aufgrund von Phasenfehlern werden jedoch manchmal kleine Abschnitte des von der Mutter geerbten Chromosoms rechnerisch mit den vom Vater geerbten parallelen Abschnitten ausgetauscht. Dies ist ein Ergebnis von technischen Fehlern, nicht von biologischen Prozessen. Wir haben diese Fehler überwunden, indem wir die Größe der Lücken, die wir zusammenfügen, vergrößern und dabei genau kalibrieren, um die Einführung neuer Fehler zu vermeiden.
Der letzte Schritt des DNA-Matchings besteht darin, falsche Positive herauszufiltern und die spezifische Beziehung zwischen zwei Individuen mit gemeinsamen DNA-Segmenten zu schätzen. Weil viele von uns Nachkommen der gleichen sehr alten Vorfahren sind, haben wir oft winzige gemeinsame DNA-Segmente mit Individuen, die wir nicht wirklich als Familie betrachten würden. Wir haben nach einer Methode gesucht, um solche Übereinstimmungen, die Genealogen nur frustrieren, herauszufiltern. Zu diesem Zweck messen wir Fehlalarme intern, indem wir Trios betrachten – das sind Sätze von Kind, Mutter und Vater, die alle mit MyHeritage DNA-Kits getestet wurden und Ergebnisse erhielten, die bestätigten, dass die Beziehungen zwischen Eltern und Kind korrekt sind. Jede Übereinstimmung, die ein Kind mit einer anderen Person hat, die weder dem Vater noch der Mutter entspricht, wird als falsch positiv gewertet und wird als Nur-Kind-Übereinstimmung bezeichnet. Wir messen den Prozentsatz von Nur-Kind-Übereinstimmungen unter allen Übereinstimmungen, die für Kinder in allen bekannten Trios auf MyHeritage zurückgegeben werden, und diese Zahl wird als Prozentsatz von mutmaßlichen Falsch-Positiven bezeichnet, die durch Nur-Kind-Übereinstimmungen angezeigt werden. Wir haben es geschafft, diese Zahl auf 16-20 Prozent zu senken, was ein gutes Ergebnis ist, das, soweit wir wissen, verglichen mit allen anderen DNA-Diensten gleichwertig oder sogar besser ist. Unsere verbesserten Klassifikatoralgorithmen haben es geschafft, unsere Falsch-Positive-Quote auf ein Allzeittief zu bringen.
Aber wir haben nicht damit aufgehört. Wir wollten eine Methode entwickeln, mit der ihr eure Genealogie-Suche am effektivsten machen könnt. Dafür haben wir unsere statistischen Algorithmen verwendet, um die Übereinstimmungen in Übereinstimmungen mit hohem, mittlerem und niedrigem Vertrauen zu kategorisieren. Übereinstimmungen mit niedrigem oder mittlerem Vertrauen werden auf der Website als solche gekennzeichnet. Dies sind DNA-Übereinstimmungen, die mit Skepsis behandelt werden sollten, da sie das Risiko bergen, falsch-positiv zu sein. Solche Übereinstimmungen weisen typischerweise sehr wenige, sehr kleine gemeinsame DNA-Segmente auf. Somit könnt ihr eure Zeit optimal nutzen. Folgt zuerst den Matches mit hohem Vertrauen und wenn ihr Lust auf eine Herausforderung habt, durchsucht die unteren und mittleren Werten nach versteckten Schätzen ab. Beachtet, dass Übereinstimmungen mit niedrigem und mittlerem Vertrauen von den wöchentlichen Benachrichtigungs-E-Mails für neue Übereinstimmungen ausgeschlossen sind.
Die neuen Klassifikatoren sind so gut, dass der Prozentsatz der Nur-Kind-Übereinstimmungen, die nicht als niedrige oder mittlere Vertrauenswürdigkeit gekennzeichnet sind, jetzt weniger als 5% beträgt. Mit anderen Worten, wenn ihr ein DNA-Match auf MyHeritage überprüft, das nicht als niedriges Konfidenzniveau oder mittleres Konfidenzniveau markiert ist, könnt ihr jetzt fast sicher sein, dass ihr eure Zeit nicht mit einem falsch positiven Ergebnis verschwendet. Wenn es sich bei dem Match, das ihr überprüft, um einen Cousin oder einen Cousin zweiten Grades handelt, gibt es so viel geteilte DNA, dass ihr sicher sein könnt, dass es kein falsch positives Ergebnis ist.
Die Genauigkeit der Schätzung einer Beziehung einer DNA-Übereinstimmung wird unter Verwendung von zwei Parametern gemessen, die als Erinnerung und Präzision bezeichnet werden. Perfekte Genauigkeit bedeutet, dass dem Nutzer jedes Mal die korrekte Beziehung zu einem DNA-Match mitgeteilt wird (Rückruf), während nur diese Beziehung vorgeschlagen wird und nicht eine größere Bandbreite möglicher Beziehungen (Präzision). Wenn zum Beispiel zwei Individuen tatsächlich Geschwister sind, wird ein perfekter Algorithmus vorschlagen, dass sie Geschwister sind; es wird nicht geschätzt, dass sie entweder Geschwister oder Cousins sind. (Allerdings ist dieser theoretisch perfekte Algorithmus aufgrund der Natur der DNA-Vererbung nicht möglich). MyHeritage kann nun DNA-Übereinstimmungen für entfernte Verwandte wie Cousins 4. oder 5. Grades vorschlagen, was unglaublich schwierig ist. Für nähere Verwandte ist die Genauigkeit viel höher und liegt nahe bei 100%. Zur gleichen Zeit werden wir nur ungefähr 2 oder 3 mögliche Beziehungen für DNA-Matches vorschlagen, die Cousins ersten Grades oder näher sind. Für entfernte Cousins werden wir einen Durchschnitt von bis zu 5 möglichen Beziehungen zeigen – eine relativ kleine Bandbreite. Die Genauigkeit und der Erinnerungswert von MyHeritages Beziehungsschätzungen sind jetzt viel besser als vorher.
Wir haben die hohe Qualität unseres neuen DNA-Matching-Algorithmus validiert, indem wir neue DNA-Match-Listen mit denen anderer DNA-Unternehmen verglichen haben, und die Ergebnisse sind sehr ähnlich.
Bestimmte besonders endogame Bevölkerungen, wie aschkenasische Juden, stellen eine einzigartige Herausforderung für das DNA-Matching dar. Da diese Populationen eine signifikante Mischehe aufwiesen, haben nicht genealogisch verwandte Individuen innerhalb dieser Population mehr gemeinsame DNA, als man es sonst für Nicht-Verwandte erwarten würde. MyHeritage hat sich mit einen zusätzlichen Klassifizierungsalgorithmus beschäftigt, der maschinelles Lernen verwendet, um Ashkenazi-Beziehungen mit höherer Auflösung als jeder andere DNA-Dienst zu klassifizieren. Wir haben diesen Klassifikator verwendet, um eine bessere Ablehnung von falsch Positiven für aschkenasische Juden zu erreichen und sie auf das gleiche Niveau falscher Positiver wie die der allgemeinen Bevölkerung zu bringen.
Was bedeuten diese Verbesserungen für MyHeritage DNA-Nutzer?
Jetzt erhaltet ihr:
Genauere DNA-Übereinstimmungen
Etwa 10 mal so viele DNA-Übereinstimmungen
Spezifischere und genauere Beziehungsschätzungen
Hinweise auf das DNA Übereinstimmungs-Vertrauensniveau, um euch auf eure Forschung konzentrieren zu können
Chromosomenbrowser
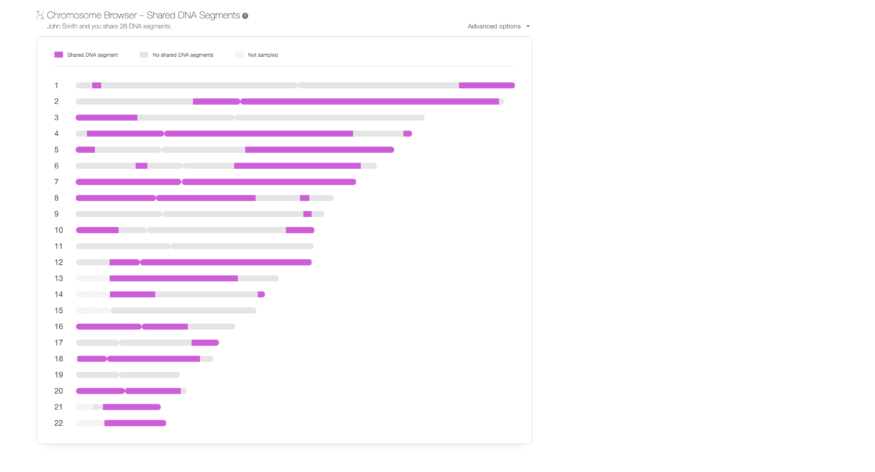
Zusammen mit den Genauigkeitsverbesserungen haben wir auch neue Funktionen hinzugefügt, um die Verwendung von DNA-Matches zu verbessern. Die erste, auf vielfachem Wunsch, ist ein Chromosomenbrowser für gemeinsame DNA-Übereinstimmungen. Es wurde zur Seite „DNA Match Überprüfung“ hinzugefügt.

Ein Chromosomenbrowser ist eine schematische Darstellung der Chromosomen einer Person, in der DNA-Segmente visualisiert werden können. Viele unserer Nutzer haben einen Chromosomenbrowser angefordert und wir wissen, dass dies ein wichtiges Werkzeug für Genealogen ist. Daher haben wir versprochen, dass wir eines entwickeln werden und jetzt haben wir dieses Versprechen erfüllt. Der neue Chromosomenbrowser auf MyHeritage ist eine erste Version, die in Kürze noch erweitert wird und für die Betrachtung gemeinsamer DNA-Segmente für jedes DNA-Match gedacht ist. Es ist eine kostenlose Funktion, die von allen Nutzern von MyHeritage verwendet werden kann, die den DNA-Test durchgeführt oder DNA-Daten hochgeladen haben. Es zeigt die geteilten Segmente zwischen euch und einem DNA-Match in Lila. Wenn ihr mit der Maus über ein freigegebenes Segment geht, könnt ihr die genomische Position des gemeinsamen Segments, die Größe des Segments und die Anzahl der SNPs dort sehen. Graue Segmente wurden nicht mit dem DNA-Match geteilt und die kreuz und quer verlaufenden Abschnitte wurden aufgrund des Fehlens von SNPs in diesen Regionen nicht analysiert. Beachtet, dass, obwohl wir niemals einem anderen Nutzer erlauben würden, eure rohen DNA-Daten herunterzuladen, sollte ein anderer Nutzer ein gemeinsames Segment mit euch haben und seine Details (Position und Größe) sehen können, indem er die Informationen dieses Segments auf seiner eigenen DNA überprüft , kann dieser andere Nutzer die Genotypen, die ihr in eurer DNA in diesem bestimmten Segment habt, ableiten. Nutzer, die lieber verhindern möchten, dass andere Nutzer, die ihrer DNA entsprechen, die Details von freigegebenen Segmenten anzeigen, können diese Funktion deaktivieren, indem sie eine neue Datenschutzeinstellung verwenden, die wir für diesen Zweck hinzugefügt haben.
Der Chromosomenbrowser bietet auch die Möglichkeit, Daten über gemeinsame Segmente herunterzuladen. Dies ist über das Menü „Erweiterte Optionen“ in der oberen rechten Ecke des Chromosomenbrowsers zugänglich. Fortgeschrittene Nutzer können diese Option verwenden, um Informationen über die freigegebenen Segmente herunterzuladen und sie dann zum Anzeigen in anderen Tools oder Chromosomenbrowsern zu verwenden. In Kürze werden weitere Funktionen verfügbar sein, z. B. die gleichzeitige Anzeige von drei oder mehr gemeinsamen Segmenten von DNA-Matches. Wenn ihr die gemeinsamen Segmente mehrerer DNA-Übereinstimmungen gleichzeitig angezeigt bekommt, könnt ihr den gemeinsamen Vorfahren zurückverfolgen und den identifizieren, der das Segment an alle DNA-Übereinstimmungen weitergegeben hat, und dann herausfinden, wie ihr alle miteinander verwandt seid. Wir planen außerdem, die vom Chromosomenbrowser angezeigten gemeinsamen Segmente bald als Druckversion zur Verfügung zu stellen.
Mit einiger Übung sind wir zuversichtlich, dass unsere Nutzer die neue Funktion „Chromosomenbrowser“ verwenden können, um bestimmte Segmente in ihrer DNA und Vorfahren zu identifizieren, bessere Einsichten in ihre DNA-Übereinstimmungen zu erhalten und den Beziehungspfad besser zu verstehen. Wir hoffen, dass dies unserer Community helfen wird, Mauern zu durchbrechen, ihre Herkunft zu verfolgen und zu verstehen, wie sie mit Familienmitgliedern, die über die DNA-Matches entdeckt wurden, verwandt sind.
Facelift und leichtere Navigation
Im Rahmen dieses Updates haben wir die Benutzeroberfläche der DNA-Übereinstimmungen überarbeitet, um eine bessere Übereinstimmung mit den anderen DNA-Bildschirmen zu erreichen. Die meisten dieser Änderungen sind klein und kaum wahrnehmbar, z. B. Schaltflächen auf der Liste der DNA-Übereinstimmungen, die lila statt orange sind. Eine weitere sinnvolle Verbesserung ist jedoch, dass die Listenseite „DNA-Übereinstimmung“ jetzt die Details des DNA-Kits anzeigt. Wenn ihr also durch die Liste scrollt, verliert ihr nie den Überblick über die von euch beobachteten Übereinstimmungen.

In Arbeit
Unsere Arbeit ist nicht erledigt. Das DNA Matching ist immer in Arbeit und wird von uns in Zukunft ständig verbessert. Die wachsende Größe unserer DNA-Datenbank sowie die zunehmende Verbindung zwischen DNA-Kits und Stammbäumen bieten uns mehr Möglichkeiten, die DNA-Matching-Algorithmen zu optimieren, und wir beabsichtigen, dies regelmäßig zu tun und die Genauigkeit weiter zu verbessern.
In Bezug auf DNA-Daten, die von anderen Diensten hochgeladen werden, unterstützen wir immer noch keine DNA-Übereinstimmung mit DNA-Kits, die auf dem Illumina-GSA-Chip basieren. Dazu gehören Kits von 23andMe (aktuelle Version V5) und Living DNA. Wir unterstützen DNA-Daten von GSA-Chips, die in unserem Labor verarbeitet werden können. es ist in ziemlich guter Form, aber immer noch nicht perfekt, also haben wir uns entschieden, es von dieser Veröffentlichung auszuschließen, bis es perfektioniert ist. Dies wird in den nächsten Monaten hinzugefügt.
Ethnische Schätzungen sind getrennt vom DNA-Matching und die hier beschriebenen Verbesserungen haben keine Auswirkungen auf ethnische Schätzungen. Wir planen in den nächsten Monaten eine Aktualisierung unserer Ethnizitätsberichte, um deren Genauigkeit zu verbessern. Bleibt also dran!
Nächste Schritte
Bestellt ein MyHeritage DNA-Kit, um von diesen neuen Funktionen und Verbesserungen zu profitieren. Wenn ihr bereits selbst getestet habt, zieht in Erwägung, DNA-Kits für einige eurer Verwandten, insbesondere ältere, zu erwerben, um weitere Verwandte zu finden und eure eigenen Matches zu triangulieren. Wenn ihr beispielsweise einen Cousin eurer Mutter oder eures Vaters testet, können Übereinstimmungen mit neuen Verwandten, die ihr bereits gemeinsam mit diesem Cousin habt, über einen Pfad zu einem neueren Vorfahren in eurem Stammbaum führen. Der neue Chromosomenbrowser ist nützlich, um diese Übereinstimmungen zu verstehen. Wenn es also einen bestimmten Zweig in eurem Stammbaum gibt, der euch am meisten interessiert, dann erwerbt zusätzliche DNA-Kits für ältere Verwandte.
Wenn ihr eure DNA bereits an anderer Stelle getestet habt, ladet eure DNA-Daten auf MyHeritage hoch. MyHeritage ist der einzige der drei größten DNA-Diensten, die den Upload von DNA-Daten unterstützt. Nutzt dies, solange es noch kostenlos ist und erhaltet kostenlose DNA-Matches und Ethnizitätsschätzungen für eure vorhandenen Daten. Mit MyHeritage’s umfangreicher DNA-Datenbank von über einer Million Menschen, von denen die meisten nur auf MyHeritage getestet haben, ist dies ein Kinderspiel. Ihr erhaltet eure Ergebnisse kostenlos in 1-2 Tagen.
Wenn ihr bereits mehr als ein DNA-Kit auf MyHeritage verwaltet, nehmt euch bitte die Zeit, um sicherzustellen, dass jedes Kit, das ihr verwaltet, mit der richtigen Person verknüpft ist. Dies kann bei Bedarf über die Seite „DNA-Kits verwalten“, die über das DNA-Menü zugänglich ist, behoben werden. Verwendet die Option „Kit einer anderen Person zuweisen“, wenn ihr ein Kit habt, das nicht korrekt zugeordnet ist. Dies ist erforderlich, wenn alle Kits, die ihr für mehrere Verwandte hochgeladen habt, immer noch mit eurem eigenen Stammbaumprofil verknüpft sind.
Schließlich sind DNA-Kits auf MyHeritage viel nützlicher, wenn ein Stammbaum mit ihnen verbunden ist. Auf diese Weise erhaltet ihr bessere Einblicke in eure DNA-Matches, zum Beispiel durch das Vorhandensein von Smart Matches, gemeinsamen Familiennamen oder gemeinsamen Geburtsorten zwischen euch und einem beliebigen DNA-Match. Wenn ihr ein DNA-Kit auf MyHeritage habt, aber keinen Stammbaum oder einen sehr kleinen, ist es jetzt an der Zeit, einen Stammbaum zu erstellen oder euren bestehenden zu erweitern. Es wird für eure DNA-Matches von Vorteil sein, aber in erster Linie wird es für euch von Nutzen sein.
Viel Spaß,
Das MyHeritage-Team
Meinrad
13. Februar 2018
Lieber Peter
Herzlichen Dank für diese Informationen.
Gruss
Meinrad