








Sehr schönes, neues Tool. Mich würde allerdings interessieren, ob da auch die automatische Übersetzung in andere Sprachen funktioniert, will heissen: Bekomme ich ein Book Matching von einem john Smith, wenn ich einen Johannes Schmidt im Stammbaum habe??
Book Matching: Übereinstimmungen mit Büchern

Das Wochenende steht vor der Tür und wir freuen uns, Euch heute schnell noch eine neue, revolutionäre Technologie bekannt geben zu dürfen – Book Matching.
Das Book Matching sucht in unserer umfangreichen Sammlung an digitalisierten historischen Büchern, automatisch nach passenden Personen, die in den Stammbäumen auf MyHeritage eingegeben wurden. Die innovative, neue Technologie ist einzigartig auf MyHeritage. Es nutzt die semantische Analyse, um jeden Satz auf jeder Seite der digitalisierten Bücher zu verstehen, und um Übereinstimmungen mit sehr hoher Genauigkeit zu finden. Book Matching hat bereits über 80 Millionen neue Matches für unsere Nutzer produziert! Jede Übereinstimmung ist ein Absatz aus einem Buch speziell über die Person, die im Stammbaum eingetragen wurde. Sie gewährt direkten Zugang zum jeweiligen Absatz und bietet die Fähigkeit das restliche Buch zu durchsuchen.
Mit Book Matching werdet ihr faszinierende Familieninformationen entdecken, die ihr sonst nicht finden würdet. Auch neue Verwandte und Vorfahren können entdeckt werden. Verwendet diese Informationen, um euren Stammbaum zu erweitern und diesen mit Farbe zu füllen.

Im Jahre 2012 haben wir SuperSearch™ veröffentlicht, unsere Suchmaschine für historische Aufzeichnungen. Im Dezember 2015 wurde die Sammlung an digitalisierten historischen Büchern zu Supersearch™ hinzugefügt. Erst vor kurzem haben wir die Bücher in der Zusammenstellung der veröffentlichten Quellen verdreifacht, von 150.000 auf 450.000 Quellen, mit insgesamt 91 Millionen Seiten. Wir haben ein Team von hart arbeitenden Verwaltern zusammengestellt und wir planen jedes Jahr Millionen zusätzliche Seiten zur Sammlung der digitalisierten Bücher hinzuzufügen. Dazu gehören nicht nur englischsprachige Bücher, sondern auch internationale.
Die Herausforderung
Bücher sind schon immer eines der besten Quellen für die Familienforschung gewesen, aber eine effiziente Suche ist fast unmöglich gewesen. Auch nachdem Bücher fotografiert und digitalisiert wurden, und der durchsuchbare Text über die Texterkennung (OCR) erkannt wurde, musste man immer viel Zeit investieren, um brauchbare Ergebnisse zu finden. Beispiel: wenn ihr einen Hans Thomas in eurem Stammbaum habt, würde eine Textsuche in Bücher Ergebnisse für Menschen mit dem Namen Hans oder Thomas ergeben, ohne Rücksicht auf Vor- oder Nachnamen. Selbst wenn ein Hans Thomas gefunden werden würde, wäre es wahrscheinlich nicht die Person, die ihr sucht. Es gibt keine Möglichkeit, den exakten Hans Thomas zu finden, z.B. den Hans Thomas, der in den frühen 40er Jahren in Hamburg geboren wurde und der mit einer Anita Maria verheiratet war.
Book Matching hilft!
Unsere Book Matching-Technologie überwindet diese Schwierigkeiten, indem sie automatisch narrative Beschreibungen von Menschen in den historischen Büchern, einschließlich Namen, Ereignisse, Termine, Orte und Beziehungen, versteht, und diese passend mit extrem hoher Genauigkeit und Geschwindigkeit mit den 2 Milliarden Menschen in den Stammbäumen auf MyHeritage vergleicht; und dies wiederholt sich automatisch, sobald euer Stammbaum wächst oder wir weitere Bücher hinzufügen.
Eine schwierige Aufgabe leicht gemacht
Genealogische Informationen aus Büchern zu extrahieren, ist keine einfache Aufgabe. In strukturierten Dokumenten wie Geburtsurkunden oder Volkszählungen, ist die Art von Informationen in den Daten, sehr klar dargestellt. Es ist klar, wo Familiennamen, Geburtsdaten usw. zu finden sind. Auf der anderen Seite, in unstrukturierten Freitext-Daten, wie digitalisierte historische Bücher, können Fakten wie Geburtsdaten, Todesdaten und Orte auf viele verschiedene Arten und unterschiedlichen Kontexten geschrieben werden. Die Informationen haben keinen bestimmten Ort oder Ordnung. Während allgemeine Phrasen wie „Tod“, „starb“, „ging von uns“, sich alle auf den Tod einer Person beziehen können, können weniger benutzte Ausdrücke wie „beendete seine irdische Karriere“ dies auch tun. Wir haben derzeit eine große Anzahl an Regeln, um Ausdrücke zu finden, die den Tod beschreiben!
Bücher verweisen nicht oft auf eine Person über ihren vollständigen Namen; beispielsweise kann ein Absatz eine Frau mit ihrem Vornamen nennen und dann geht es mit dem Namen und die Beschreibung ihres Vaters weiter – eine spezialisierte Technologie ist notwendig, um dieses zu folgen und zu rekonstruieren. Wir haben hart gearbeitet, um zahlreiche Algorithmen zu bilden, um Familiengeschichtsinformationen aus Büchern zu erhalten. Diese wurden getestet und optimiert, iteriert und perfektioniert, um eine hohe Genauigkeit zu gewährleisten, und so viele Informationen wie möglich aus den Büchern zu sammeln. In dem Prozess, haben wir auch erfolgreich Millionen von OCR-Fehler bewältigt und berichtigt. Beispiel: wenn der OCR Prozess dachte, dass eine Person im „]\lay“ geboren wurde, verstehen wir das tatsächlich als „May“, „Apnl“ ist tatsächlich „April“, usw.
Derzeit sind einige Bücher in der Sammlung von digitalisierten Büchern doppelt zu finden, weil sie mehrmals von verschiedenen öffentlichen Gruppen eingestellt wurden. Niemand war in der Lage herauszufinden, dass einige von ihnen redundant sind. Wir setzen derzeit den letzten Schliff, eine spezielle Technologie, die in der Lage ist, die doppelten Bücher zu löschen. Sobald wir diese Arbeit abgeschlossen haben, werden die meisten doppelten Übereinstimmungen automatisch ausgeblendet.
Book Matching in Aktion:
Wir haben kürzlich einigen der führenden Genealogie-Blogger im englischsprachigen Raum ihre eigenen Book Matches gezeigt. So konnten sie aus erster Hand, die gefundenen Übereinstimmungen für ihre eigenen Stammbäume sehen. Hier zwei Beispiele für Euch:
Dick Eastman vom Eastman’s Online Genealogy Newsletter forscht seit Jahren seine Familiengeschichte. Er hat 2780 Personen in seinem Stammbaum auf MyHeritage, und erhielt um die 500 Book Matches. Die Mehrheit der Informationen aus den Book Matches war ihm neu.
Beispiel: Elizabeth Fifield, Dick’s direkter Vorfahre (8 Generationen), erschien in seinem Stammbaum nur mit Geburts-, Todesdaten und Geschwister.
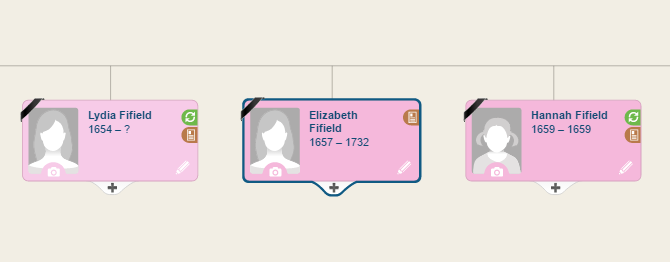
Ein automatischer Book Match wurde für Elizabeth im Buch „Genealogical and personal memoirs relating to the families of the state of Massachusetts; by Cutter, William Richard, 1847-1918“ gefunden, eine Quelle, die er – wie Dick Eastman selbst sagte – wohl nie überprüft hätte.

Der Auszug unten ist der Abschnitt, der von MyHeritage gefunden wurde. Die spannenden, neuen Informationen listen hier Elizabeth’s Ehemann und andere historische Informationen über ihn und seine Familie; wie ihre sechs Kinder und ihre Geburtsdaten. Informationen, die Dick vorher nicht hatte, und die er jetzt zu seinem Stammbaum hinzufügen konnte. So wurde eine komplette Linie zu seinem Stammbaum hinzugefügt.

Der Genealoge Randy Seaver von Genea-Musings hat über 40.000 Personen in seinem Stammbaum auf MyHeritage. Mit sage und schreibe 17.323 Book Matches, ist er nun in der Lage einen Berg an neuen Informationen über die Menschen in seinem Stammbaum ausfindig zu machen!
Zum Beispiel hat Randy einen Verwandten, William Seaver Woods, in seinem Stammbaum, Geburtsdaten sind vorhanden. Dieser wird als unverheiratet angegeben.
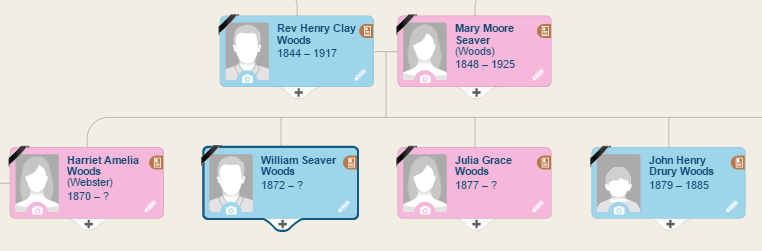
Ganz unerwartet fand MyHeritage im Jahrbuch „Alumni Record of Wesleyan University, Middle, Connecticut, 1921“ die perfekte Übereinstimmung für William.

William hat an dieser Universität studiert. Die Seite listet seine Leistungen, und erwähnt, dass er eine Frau und ein Kind hatte, welche in Randys Baum fehlen. Beachtet, dass sein Sohn Robert, den Nachnamen Crombie besitzt, der Nachname seiner Mutter Grace. Da Robert nicht die Nachnamen Seaver oder Woods verwendet hat, hätte Randy ihn wohl nicht entdeckt. Jetzt hat Randy eine frische Spur. Er kann diese Familienlinie nun erforschen und sie in die Gegenwart bringen. Etwas das vorher zu einem toten Punkt geführt hat.

Weitere interessante Beispiele könnt ihr in unserem englischen Blog nachlesen.
Die Blogger waren jedenfalls beeindruckt von diesen spannenden, nie zuvor gesehenen Übereinstimmungen, die wertvolle Informationen zu ihren Stammbäumen hinzufügt haben. Wenn Book Matching so eine enorme Menge an neuen Daten für erfahrene Genealogen anbietet, die ihre Familiengeschichte seit Jahrzehnte erforschen, dann könnt ihr euch mit Sicherheit vorstellen, dass diese auch für euch und alle anderen MyHeritage Nutzer von Bedeutung sein werden.
Die Zusammenstellung der veröffentlichten Quellensammlung ist frei zugänglich. Das Anzeigen von Book Matches erfordert ein Daten-Abonnement.
Was kommt als nächstes? Book Matching steht derzeit nur für englische Bücher zur Verfügung, aber die Technologie wird in Kürze erweitert, um andere Sprachen zu decken. Wir sind dabei unsere digitalisierten historischen Aufzeichnungen kontinuierlich zu erweitern, um die Erforschung der Familiengeschichte zu erleichtern. Wir erwarten, dass das Corpus digitalisierter Bücher auf MyHeritage sich bald verdoppelt.
Woher wisst ihr, dass ihr Book Matches habt? Meldet euch einfach auf eurer Familienseite an und überprüft eure Record Matches über den Menüpunkt „Entdeckungen“, oder ihr überprüft euren E-Mail-Posteingang auf eure Record Matches Benachrichtigungen- diese werden in den nächsten Tagen an unsere Nutzer gesendet und liefern neu gefundene Treffer. Jede Übereinstimmung, die ihr von einem Buch erhaltet, wird durch diese neue Technologie ermöglicht.
Neu auf MyHeritage? Einfach über die Homepage registrieren und den Stammbaum als GEDCOM Datei hochladen. Profitiert von den Book Matches, diese gibt es nur exklusiv auf MyHeritage. Viel Spaß!
Rosik Arkadius
8. April 2016
Ich werde überrascht mehr über meine Familie zu erfahren toll